


Tutoriel : les propriétés dynamiques
L'objectif du tutoriel est de présenter les propriétés dynamiques du formalisme nomo. Les aspects dynamiques portent à la fois sur l'adaptation des conditions des règles que sur le mécanisme de maintien et d'élimination des règles. La compréhension de ces deux aspects permettra d'élaborer une liste des différentes familles de classification possible.
Ce tutoriel s’appuiera sur le banc d'essais dédié aux nuages de points ainsi que sur les données iris-acp.pts données en exemple. Les données iris-acp.pts correspondent à trois ensembles de cinquante points à quatre dimensions. La figure ci-dessous donne la représentation de la base iris-acp.pts avec nomoSDK dont les couleurs identifient les trois espèces d'iris :
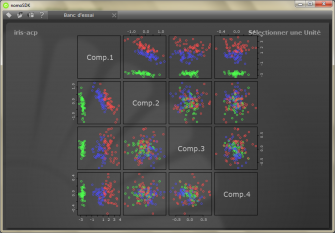
Les données du fichier iris-acp.pts sont organisées de telle sorte qu'il n'y ait pas deux points consécutifs de même espèce, soit une alternance cyclique de setosa, versicolor, et virginica.
L'analyse en composantes principales a pour conséquence de concentrer l'information pertinente dans la première composante comme le suggère l’histogramme ci-dessous des variances explicatives.

Pour l'exemple, les derniers axes, qui représentent le bruit, seront cependant conservés afin de mettre à l'épreuve la robustesse du système.
L'agent recevra tous les trois pas un nouveau point avec son étiquette. L'étiquette sert à la visualisation. L'étiquette ne doit pas être modifiable donc ne doit pas être soumise à l’adaptation. À l'étiquette est associée une commande afin de pouvoir récupérer la valeur de l'étiquette et servir à la visualisation.
La perception des points pourra être soumise à l'adaptation. Dans ce cas, la commande associée renverra un point issu d'un générateur aléatoire gaussien dont la moyenne et la variance correspondent à la prémisse d'entrée de la perception associée. Une fois la phase d'adaptation terminée, les points renvoyés via la commande correspondront aux moyennes des prémisses.
Le modèle “tutorial_2”, qui sera complété au cours du tutoriel, est le suivant :
<model name="tutorial_2" xmlns:xi="http://www.w3.org/2001/XInclude" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:project="http://www.nomoseed.org/project" xmlns="http://www.nomoseed.org/model"> <project:header> ... </project:header> <base> <xi:include href="pointsscatter.mod"/> </base> <definition> <perceptive_structure name="label"> <command_type> <items> <item name="setosa"/> <item name="versicolor"/> <item name="virginica"/> </items> </command_type> <items> <item name="setosa"/> <item name="versicolor"/> <item name="virginica"/> </items> <components> <component name="value"/> </components> </perceptive_structure> <perceptive_structure name="point"> <command_type> <items> <item name="setosa"/> <item name="versicolor"/> <item name="virginica"/> </items> </command_type> <items> <item name="setosa"/> <item name="versicolor"/> <item name="virginica"/> </items> <components> <component name="comp1"/> <component name="comp2"/> <component name="comp3"/> <component name="comp4"/> </components> </perceptive_structure> </definition> </model>
La configuration de la base de connaissance ne changera pas tout le long de cette deuxième partie du tutoriel. Le nombre d'ajustements est limité à 100.
<knowledge_base name="tutorial_2" xmlns="http://www.nomoseed.org/knowledge_base" xmlns:project="http://www.nomoseed.org/project" xmlns:sdk="http://www.nomoseed.org/sdk" > <project:header> ... </project:header> <time_span_limit value="3500ms"/> <maximum_of_maximizations value="10"/> <maximum_of_internal_events value="3"/> <maximum_of_external_events value="1"/> <maximum_of_rules_by_type value="auto"/> <maximum_of_premises value="auto"/> </knowledge_base>
Les exemples de classification sur les données “iris-acp.dat” ne visent pas à identifier précisément chacune des espèces mais à illustrer les mécanismes de classification et d'adaptation. De même, la stratégie d'initialisation des règles de base et le nombre d'ajustement modifient le résultat de la classification aussi par souci de lisibilité, la stratégie d'initialisation se veut simple et le nombre d'ajustement réduit privilégié.
Adaptation des conditions
Les capacités d'adaptation reposent sur l'ajustement des prémisses à chaque sélection de la règle si le nombre maximal d'ajustements (maximum_of_maximizations) n'a pas été encore atteint. Cet ajustement porte pour toute composante continue dont la tolérance est non nulle et non infinie.
Dans l'écriture des règles, il est possible de préciser le nombre d'ajustements (fitting_nbr) déjà effectué de sorte à conserver l'inertie d'un apprentissage déjà entrepris. Lorsque le nombre d'ajustements est omis, par défaut il prend la valeur INF de sorte que toute adaptation est interdite.
Adaptation des prédictions
Les composantes continues, comme la crédibilité et l'indice temporel ainsi que leur tolérance, peuvent être modifiés de manière à maximiser l'espérance de la sélection de la règle en fonction de ce qui lui a déjà permis d'être déclenché. La maximisation n'a pas de sens lorsque la tolérance vaut nulle ou l'infinie.
Dans le cadre d'une prédiction, et plus précisément de la règle de contrôle, la maximisation de l'indice temporel de la prémisse de type landmark correspond à l'ajustement du délai de la prédiction. La maximisation de la crédibilité de la prémisse de type perception correspond à l'ajustement de la crédibilité de la perception prédite.
L'exemple ci-dessous concernera uniquement la prédiction de la perception de setosa. La perception d'un setosa apparait cycliquement tous les 9 pas, l'ajustement du délai visera donc une constante, en revanche la crédibilité de la perception varie en fonction des données d'entrées, l'ajustement visera la moyenne.

Auparavant, le modèle devra être complété d'une structure prédictive de la manière suivante, soit “tutorial_2_ap.mod” :
<predictive_structure name="point"> <items> <item name="setosa"/> <item name="versicolor"/> <item name="virginica"/> </items> </predictive_structure> <perceptive_structure name="point"> ... <predicted_by name="point"/> </perceptive_structure>
La totalité du programme de cet exemple se trouve dans le fichier “tutorial_2_ap.prg”. La définition de la perception d'un point issue de la famille setosa sera définie par la moyenne et l'écart type comme suit :
<scheme name="label_perception"> <rule name="label_virginica"> <premise model="tutorial_2" category="input" type="label"> <information value="3" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="perception" type="label"> <information value="virginica"/> </conclusion> </rule> <rule name="point_versicolor_in"> <premise model="tutorial_2" category="perception" type="label"> <information value="virginica" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="1000 ms" tolerance="0"/> </premise> <premise model="tutorial_2" category="input" type="point"> <information value="-2.5906" tolerance="0.4300587"/> <information value="-0.1871" tolerance="0.4626638"/> <information value=" 0.013314" tolerance="0.1642161"/> <information value=" 0.00053424" tolerance="0.1211273"/> </premise> <conclusion model="tutorial_2" category="perception" type="point"> <information value="setosa"/> </conclusion> </rule> </scheme>
Pour la définition de la prédiction, le délai est volontairement plus grand que le temps prévu afin d'observer l'ajustement; de même, toutes les perceptions étant prises en compte, une tolérance infinie aurait pu être appliquée à la crédibilité de la prémisse perceptive. Par ailleurs, dans les paramètres de la base de connaissances, le coefficient de couverture check_cover sera mis à 3 dans le fichier tutorial_2.bas.
<scheme name="setosa_prediction"> <rule name="setosa_prediction"> <premise model="tutorial_2" category="perception" type="label"> <information value="virginica" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <premise model="tutorial_2" category="prediction" type="point" inhibitor="true"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <conclusion model="tutorial_2" category="prediction" type="point"> <information value="setosa" delay="2000 ms"/> </conclusion> </rule> <rule name="setosa_landmark"> <premise model="tutorial_2" category="perception" type="label"> <information value="virginica" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <premise model="tutorial_2" category="prediction" type="point" inhibitor="true"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <conclusion model="tutorial_2" category="landmark" type="point"> <information value="setosa"/> </conclusion> </rule> <rule name="setosa_check" fitting_nbr="0"> <premise model="tutorial_2" category="perception" type="point"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="0.5"/> <timespan value="0" tolerance="0"/> </premise> <premise model="tutorial_2" category="landmark" type="point"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="2000 ms" tolerance="500"/> </premise> <premise model="tutorial_2" category="prediction" type="point"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <conclusion model="tutorial_2" category="check" type="point"> <information value="setosa"/> </conclusion> </rule> </scheme>
Le chronogramme de la première prédiction est le suivant :
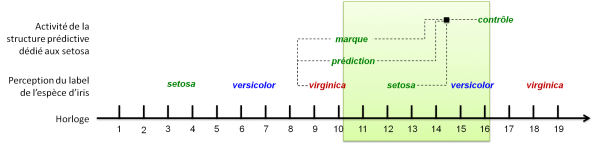
Afin de visualiser la fin de l'évaluation de la prédiction, une règle de commande affichant un point peut être introduite. La tolérance sur la crédibilité de la prémisse de contrôle permet de considérer uniquement les évaluations réussies, ce qui n'est pas le cas pour la première évaluation avant ajustement.
<rule name="point_setosa_out"> <premise model="tutorial_2" category="check" type="point"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="0.05"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="point"> <information value="setosa"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> </conclusion> </rule>
L'évolution de l'indice temporel de la prémisse de marquage contenue dans la condition de la règle de contrôle tend vers 1000 ms, avec un nombre maximal d'ajustement de 20 et sur 900 pas. La figure suivante représente cette évolution en fonction de la sélection de la règle de contrôle :
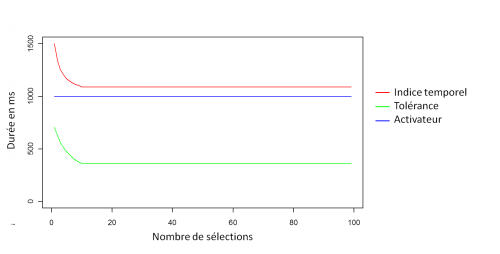
Cette évolution impacte directement la durée de l'évaluation, ci-dessous l'indice temporel de la prédiction plus la tolérance fois le coefficient de couverture check_cover, ici 3, en fonction de la sélection de la règle de contrôle :
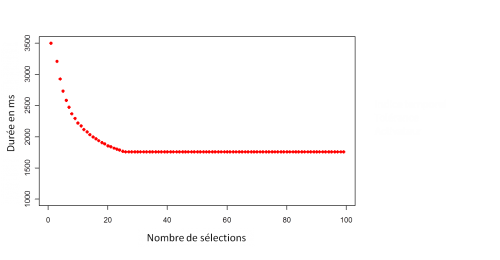
L'ajustement de la crédibilité de la prémisse de perception contenue dans la condition de la règle de contrôle revient à calculer la crédibilité moyenne de la perception (dans le graphique ci-dessous il correspond à l'activateur) et son écart type, en fonction de la sélection de la règle de contrôle :
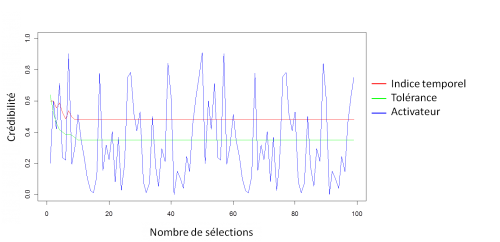
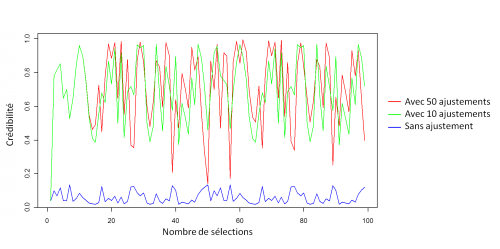
Compte tenu de la simplicité de l'exemple, l'augmentation du nombre d'ajustement maximal autorisé maximum_of_maximizations a une faible incidence comme le montre le graphique ci-dessous. En effet, l'ajustement de l'indice temporel dés la première valeur suffit à corriger l'essentiel de la prédiction.
Adaptation des entrées
Le premier exemple consiste à réaliser un apprentissage supervisé. Autrement dit, adapter les prémisses des règles de perception avec les dix premières valeurs qui permettront leur sélection puis appliquer ces règles sur les données restantes.
Dans cet exemple, l'agent doit distinguer la phase d'apprentissage de la phase d’exploitation. De plus, une phase d’initialisation doit être rajouté afin de synchroniser les premières valeurs avec la phase d'apprentissage. Le programme complet de cet exemple se trouve dans le fichier tutorial_2_as.prg. La modélisation de ces trois phases passe par l'ajout d'un type de conception dans le modèle précédent, soit le fichier “tutorial_2_as.mod” :
<conception_type name="phase"> <items> <item name="initialization"/> <item name="learning"/> <item name="explotation"/> </items> </conception_type>
La gestion des phases s'effectue avec les trois règles suivantes, chacune ne devant être déclenchée qu'une seule fois :
<scheme name="phases_management"> <rule name="initialization_phase"> <premise model="tutorial_2" category="conception" type="phase" inhibitor="true"> <information value="learning" tolerance="INF"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="conception" type="phase" inhibitor="true"> <information value="learning" tolerance="INF"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="INF"/> </premise> <conclusion model="tutorial_2" category="conception" type="phase"> <information value="initialization" delay="1500 ms"/> </conclusion> </rule> <rule name="learning_phase"> <premise model="tutorial_2" category="conception" type="phase"> <information value="initialization" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="conception" type="phase"> <information value="learning" delay="45000 ms"/> </conclusion> </rule> <rule name="exploitation_phase"> <premise model="tutorial_2" category="conception" type="phase"> <information value="learning" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="conception" type="phase"> <information value="exploitation" delay="MAX"/> </conclusion> </rule> </scheme>
Le délai de la règle learning_phase correspond au nombre d'ajustement maximal par espèce d'iris, soit 30 ajustements, fois le nombre de pas entre les perceptions (3 pas) et la période de l'horloge de 500ms, la durée de la phase d'apprentissage est de 10 x 3 x 3 x 500 = 45000ms.
Afin que les règles de perception des labels jouent un rôle uniquement pendant la phase d'apprentissage, une prémisse supplémentaire est ajoutée à leur condition, par exemple celle dédiée au Sétosa :
<rule name="label_setosa_in"> <premise model="tutorial_2" category="conception" type="phase" inhibitor="true"> <information value="exploitation" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="input" type="label"> <information value="1" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="perception" type="label"> <information value="setosa"/> </conclusion> </rule>
Les règles de perception des points sont en logique négative, elles sont toujours éligibles sauf si des labels spécifiques sont présents. L'apprentissage s'appuie sur la connaissance de l'organisation des données de telle sorte que l'étiquette, à un instant donné, permet de déduire l'étiquette du point suivant. Par exemple, la règle de perception des points point_setosa_in est inhibée par le dernier label setosa ou versicolor qui ne peut être présent uniquement pendant la phase d'apprentissage. Si ces deux labels sont absents pendant la phase d'apprentissage, cela signifie que le dernier label est virginia, le label précédent obligatoirement stetosa.
L'initialisation des prémisses d'entrée sont arbitraires tout en restant dans les ordres de grandeurs, ici la moyenne initiale correspond à la moyenne des extremums de l’ensemble des données et l'écart type à la différence entre ces extremums. L’adaptation des règles commence avec un nombre d'ajustements nul et s'arrêtera après 10 ajustements comme précisé dans tutorial_2.bas. Ainsi, comme pour les deux autres espèces, la règle point_setosa_in s'écrit de la manière suivant :
<rule name="point_setosa_in" fitting_nbr="0"> <premise model="tutorial_2" category="conception" type="phase" inhibitor="true"> <information value="initialization" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="label" inhibitor="true"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="1000 ms" tolerance="0"/> </premise> <premise model="tutorial_2" category="perception" type="label" inhibitor="true"> <information value="versicolor" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="1000 ms" tolerance="0"/> </premise> <premise model="tutorial_2" category="input" type="point"> <information value="0.2859208" tolerance="2.339816"/> <information value="0.05409695" tolerance="0.8800454"/> <information value="0.0330093" tolerance="0.4817708"/> <information value="6.47225e-05" tolerance="0.3369132"/> </premise> <conclusion model="tutorial_2" category="perception" type="point"> <information value="setosa"/> </conclusion> </rule>
Les règles de commande de type label permettent de colorier le point et éventuellement le point de la commande de type point en fonction de sa classification par l'agent après la phase d'apprentissage :
<rule name="label_setosa_out"> <premise model="tutorial_2" category="conception" type="phase"> <information value="exploitation" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="point"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="label"> <information value="setosa"/> <output value="1"/> </conclusion> </rule>
Les règles de commande de type point permettent de placer le point correspondant soit aux moyennes de la prémisse de la perception associée si le maximum d'ajustement (maximum_of_maximizations) est dépassé, soit un point issu de la distribution de probabilité définie par la prémisse de la perception associée. Ici, de part la durée de la phase d'apprentissage par rapport au nombre d'ajustement maximum, seul le premier cas est autorisé :
<rule name="point_setosa_out"> <premise model="tutorial_2" category="conception" type="phase"> <information value="exploitation" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="point"> <information value="setosa" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="point"> <information value="setosa"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> </conclusion> </rule>
Ci-dessus, les sorties des règles de commandes sont initialisées mais en définitive, étant associées à des règles de perception, leurs valeurs seront en fonction des prémisses d'entrées de ces dernières.
Après avoir effectué 453 pas (soit (150 + 1) x 3), soit parcouru l'ensemble des données une fois, le graphique ci-dessous illustre le résultat de la classification après un apprentissage sur les 30 premières perceptions. La couleur des cercles représente leur appartenance à l'une des trois espèces d'iris. Le couleur de remplissage de ces cercles représente le résultat de la classification par l'agent. Ainsi, les trente premières perceptions servant à l'apprentissage correspondent au cercle vide.

Les distributions des iris n'étant pas gaussiennes, la classification, avec uniquement un nombre de noyaux gaussiens correspondant au nombre de classe, possède inévitablement des erreurs même après une ACP. Une classification hiérarchique peut toutefois être envisagée pour dépasser ces limites.
Pertinence et oubli des règles
La pertinence évalue l'activité d'une règle au cours de son existence. La crédibilité évalue l'adéquation entre une règle et la base de faits, la pertinence évalue l'utilité de la règle au cours de l'activité de l'agent.
La pertinence augmente lorsque la règle est souvent sélectionnée ou si elle est identifiée comme bénéfique via des règles de récompense. La pertinence d'une règle diminue au cours du temps et d'autant plus si sa condition est redondante avec celle d'autres règles.
Mais une pertinence initialisée à 1 est considérée tout au cours de l’activité de l'agent comme totalement pertinente et ne pourra en aucun cas être oubliée.
Initialisation d'état interne
Après chaque évaluation des règles, le moteur d'inférence élimine toute règle dont la pertinence se trouverait inférieure ou également au seuil de l'oubli. Ainsi, dans le cas extrême où une règle serait initialisée avec une pertinence à zéro, elle reste éligible lors de la première interprétation puis serait automatiquement éliminée.
Ce mécanisme peut être intéressant dans le cas, par exemple, des règles servant à l'initialisation d'états internes.
Dans l'exemple précédent, les phases d'apprentissage et d'exploitation sont gérées réciproquement par deux règles. La règle “initialization_phase” sert uniquement à initialiser l'agent avec une intension initialization qui représente le délai avant l’enclenchement de la phase d'apprentissage et se déclenche dès la premières interprétation pour ensuite toujours rester inhibée. Afin de ne pas surcharger la base de règle, elle peut alors se réécrire de la manière suivante :
<scheme name="phases_management"> <rule name="initialization_phase" relevance="0"> <conclusion model="tutorial_2" category="conception" type="phase"> <information value="initialization" delay="1500 ms"/> </conclusion> </rule> ... </scheme>
Élimination des règles inactives
Les règles “learning_phase” et “exploitation_phase” doivent être sélectionnées une seule et unique fois. La première devient obsolète après sa sélection au cinquième pas lorsque l'intention placée initialement par la règle “initialization_phase” se réalise. La seconde devient obsolète après 5 pas due à l'initialisation plus 90 pas qui correspondent au délai de la réalisation de l'intention placée par la règle “learning_phase”, soit 2500 + 45000 ms. La règle “initilization_phase”fut éliminée directement car elle avait une pertinence nulle, ici faut que la pertinence des règles soit suffisamment élevée pour maintenir jusqu'à leur utilisation mais non maximale afin qu'à terme, elle puisse être oubliée.
Dans le cas où il n'y a pas de compétition entre les règles, les taux d'enchère et de remboursement sont nuls de sorte que seuls le taux de la taxe, le seuil de l'oubli et la pertinence initiale de la règle déterminent le moment où celle-ci sera oubliée. Ici, seules les règles “exploitation_phase” et “initialization_phase” seront utilisées pour illustrer ce mécanisme.
La simulation de l'évolution de la pertinence grâce à l'équation exprimant la dynamique de la pertinence permet de déterminer les valeurs de ces paramètres. Avec un taux de la taxe sera placé à 0.01 et un seuil de 0.1, il devient possible d'évaluer la pertinence initiale de la règle “initialization_phase” à 0.104 et celle de la règle “exploitation_phase” à 0.23, le seuil au alentour de 0.01 afin d'éliminer les règles respectivement après 5 pas et environ 100 pas, comme le montre la courbe de l'évolution de la pertinence au cours d'interprétations successives avec en rouge la zone de l'oubli :
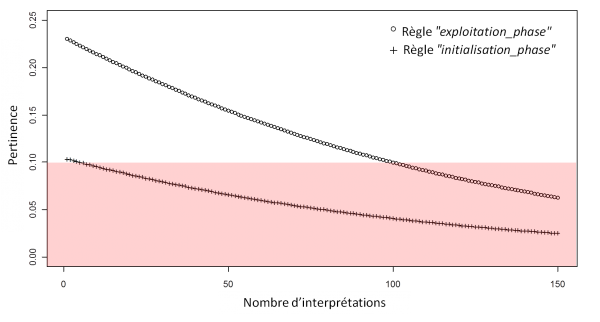
Ainsi, dans ce cas de figure, toute les règles servant à la gestion des phases d'apprentissage et d'exploitation seront éliminées après leur utilisation.
Il est également possible de programmer l'élimination des règles de perception des labels une fois la phase d'apprentissage terminée. Dans ce cas, il suffit d'initialiser les pertinences également à 0.23. En effet, ici, le taux d'enchère et celui de remboursement étant nuls, la décroissance des règles ne varie pas en fonction de leur utilisation.
Dans le cas où une compétition entre les règles est introduite, c'est-à-dire que les taux d'enchère et de remboursement sont non nuls, l'élimination des règles subit un délai du au remboursement suite à la sélection de la règle. En mettant, un taux d'enchère et de remboursement à 0.6, l'évolution de la pertinence des règles devient comme suit, avec en rouge la zone de l'oubli :
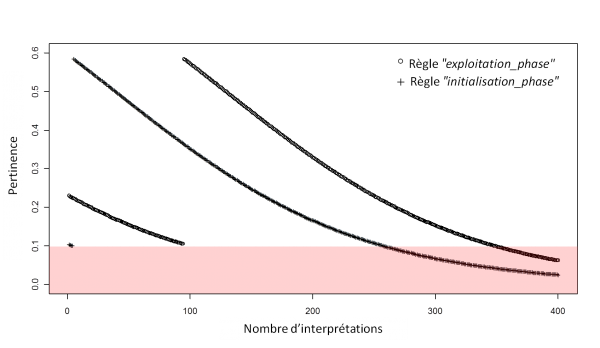
Attention, le fait que l'élimination de ces règles soit différé ne doit pas poser de problème logique. Contrairement, à l'oubli des règles ayant une pertinence nulle, la condition des règles ne peut être simplifiée, ici, l'oubli a pour but d'alléger le moteur d'inférence.
Élimination de la redondance
Lorsque deux règles possèdent des conditions très proches, il y a une certaine redondance sur les conditions. Cependant, le résultat d'une interprétation conduit à la sélection d'une seule. Dans le cadre d'une dynamique sur la pertinence, une compétition est favorisée par la notion d'enchère et de remboursement. Plus une règle se trouve proche d'une autre, plus sa pertinence décroît toutefois si cette décroissance se trouve compensée en cas de sélection. Les paramètres de cette dynamique ont été choisis arbitrairement comme suit :
<inference_engine> <frequency value="2"/> <forget value="0.1"/> <check_cover value="1.0"/> <bid_rate value="0.6"/> <reimbursement_rate value="0.6"/> <reward_rate value="0"/> <tax_rate value="0.01"/> </inference_engine>
Plus bid_rate est élevé par rapport à reimbursement_rate, plus la redondance est bannie et la phase de compétition entre les règles diminue. A l'inverse, un reimbursement_rate plus élevé conduira à l’allongement de phase de compétition.
L'exemple ci-dessous illustre le mécanisme d'élimination des règles redondantes en proposant d'effectuer une classification hiérarchique semi-supervisée, c'est à dire que les labels des premiers points d'iris sont explicites au cours de la phase d'apprentissage mais cet apprentissage peut viser n'importe lequel des deux noyaux gaussiens servant à décrire la classe. Les choix entre les deux noyaux gaussiens (soit entre deux règles) dépendent uniquement de leur espérance.
Autrement dit, pour chacune des trois espèces d'iris, deux règles de perception décrivent un groupe d'iris. Les items de la structure perceptive points doivent donc être doublés. Par ailleurs, afin de garder une seule couleur de label par classe pour visualiser le résultat de la classification, l'ajout d'un type de conception iris modélisant le concept des trois espèces d'iris, définit comme suit, soit le fichier “tutorial_2_ass.mod” :
<perceptive_structure name="point"> <command_type> <items> <item name="setosa_1"/> <item name="setosa_2"/> <item name="versicolor_1"/> <item name="versicolor_2"/> <item name="virginica_1"/> <item name="virginica_2"/> </items> </command_type> <items> <item name="setosa_1"/> <item name="setosa_2"/> <item name="versicolor_1"/> <item name="versicolor_2"/> <item name="virginica_1"/> <item name="virginica_2"/> </items> <components> <component name="comp1"/> <component name="comp2"/> <component name="comp3"/> <component name="comp4"/> </components> </perceptive_structure> <conception_type name="iris"> <items> <item name="setosa"/> <item name="versicolor"/> <item name="virginica"/> </items> </conception_type>
Les perceptions supplémentaires sont définies de la même manière que les précédentes. Cela signifie qu'au début de l'apprentissage, les règles d'une même espèce sont fortement en concurrence. Le programme complet se trouve dans le fichier “tutorial_2_ass.prg”.
La gestion des phases demeure inchangée hormis que la phase d'apprentissage s'allonge de 45000ms à 90000ms afin de prendre en compte les règles supplémentaires à ajuster.
La définition concrète du concept d'iris repose sur la détection d'une perception des deux perceptions décrivant une partie du concept d'iris. Dans le cas du concept d'iris setosa, celui-ci est sélectionné dès l'apparition de la perception setosa_1 ou setosa_2. La notion de concept d'iris n'étant valable uniquement pendant la phase d'exploitation, une prémisse validant cet état de fait appartient également à la condition des règles définissant concrètement le concept d'iris.
Ci-dessous, les macros permettant de définir l'ensemble des règles de l'exemple hormis les règles de gestion :
<macro xmlns="http://www.nomoseed.org/sdk" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" active="true" name="labels" xsi:type="template"> <csv xsi:type="embedded"> label, data, scheme, rule_in, rule_out setosa, 1, label_setosa, label_setosa_in, label_setosa_out versicolor, 2, label_versicolor, label_versicolor_in, label_versicolor_out virginica, 3, label_virginica, label_virginica_in, label_virginica_out </csv> <template xmlns="http://www.nomoseed.org/template"> <scheme name="#scheme"> <rule name="rule_in" fitting_nbr="INF" relevance="1"> <premise model="tutorial_2" category="conception" type="phase" inhibitor="true"> <information value="exploitation" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="input" type="label"> <information value="#data" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="perception" type="label"> <information value="#label"/> </conclusion> </rule> <rule name="rule_out"> <premise model="tutorial_2" category="conception" type="iris"> <information value="#label" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="label"> <information value="#label"/> <output value="#data"/> </conclusion> </rule> </scheme> </template> </macro> <macro xmlns="http://www.nomoseed.org/sdk" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" active="true" name="points" xsi:type="template"> <csv xsi:type="embedded"> percept, label_inhibitor_1, label_inhibitor_2, scheme, rule_in, rule_iris, rule_out, iris setosa_1, setosa, versicolor, point_1_setosa, point_1_setosa_in, point_1_setosa, point_1_setosa_out, setosa setosa_2, setosa, versicolor, point_2_setosa, point_2_setosa_in, point_2_setosa, point_2_setosa_out, setosa virginica_1, virginica, setosa, point_1_virginica, point_1_virginica_in, point_1_virginica, point_1_virginica_out, virginica virginica_2, virginica, setosa, point_2_virginica, point_2_virginica_in, point_2_virginica, point_2_virginica_out, virginica versicolor_1, versicolor, virginica, point_1_versicolor, point_1_versicolor_in, point_1_versicolor, point_1_versicolor_out, versicolor versicolor_2, versicolor, virginica, point_2_versicolor, point_2_versicolor_in, point_2_versicolor, point_2_versicolor_out, versicolor </csv> <template xmlns="http://www.nomoseed.org/template"> <scheme name="#scheme"> <rule name="#rule_in" fitting_nbr="0" relevance="0.9"> <premise model="tutorial_2" category="conception" type="phase" inhibitor="true"> <information value="initialization" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="label" inhibitor="true"> <information value="#label_inhibitor_1" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="1000 ms" tolerance="0"/> </premise> <premise model="tutorial_2" category="perception" type="label" inhibitor="true"> <information value="#label_inhibitor_2" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="1000 ms" tolerance="0"/> </premise> <premise model="tutorial_2" category="input" type="point"> <information value="0.2859208" tolerance="2.339816"/> <information value="0.05409695" tolerance="0.8800454"/> <information value="0.0330093" tolerance="0.4817708"/> <information value="6.47225e-05" tolerance="0.3369132"/> </premise> <conclusion model="tutorial_2" category="perception" type="point"> <information value="#percept"/> </conclusion> </rule> <rule name="#rule_iris"> <premise model="tutorial_2" category="conception" type="phase"> <information value="exploitation" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="point"> <information value="#percept" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="conception" type="iris"> <information value="#iris"/> </conclusion> </rule> <rule name="#rule_out"> <premise model="tutorial_2" category="conception" type="phase"> <information value="exploitation" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="-1" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="point"> <information value="#percept" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="500 ms" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="point"> <information value="#percept"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> </conclusion> </rule> </scheme> </template> </macro>
Au terme de la phase d'apprentissage, les règles de perceptions restantes n'ont pas obligatoirement atteint le nombre d'ajustement autorisé. En effet, le nombre de sélection et son maintien dans la mémoire dépendent de la dynamique et de la contingence des données. Aussi, la phase d'adaptation perdure encore un peu après le déclenchement de la phase d'exploitation.
Après deux présentations successives de la base de donnée “iris-acp.pts”, deux classes ne possèdent plus qu'une seule perception pour décrire un concept d'iris et une classe continue d'utiliser deux perceptions pour décrire le concept versicolor.
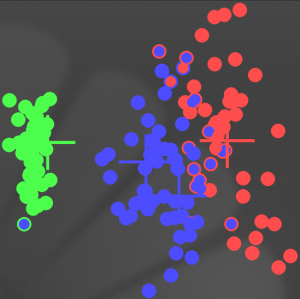
A titre de comparaison, le résultat de la classification présentée et celui de l'exemple précédent s'illustrent réciproquement par ces deux graphiques où les deux croix bleues indiquent les centres des noyaux gaussiens.
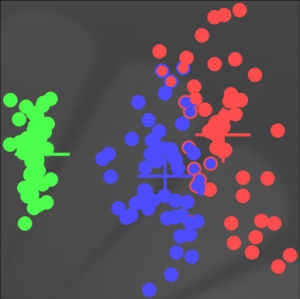
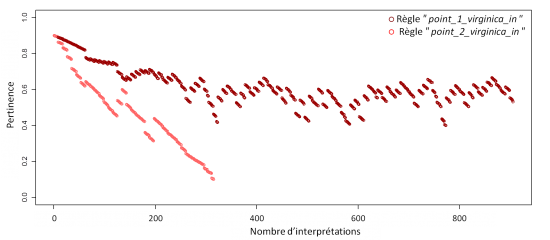
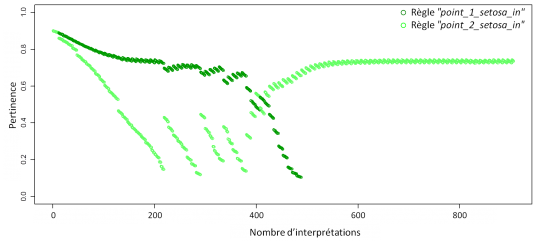
L'évolution de la pertinence permet de comprendre le résultat de la complétion entre les règles. Concernant les règles destinées à décrire le concept de virginica, la compétition fut rapide, la règle “point_2_virginica_in” bien que sélectionnée quelque fois ne parvient pas à s'imposer et est oubliée. Dans ce contexte, seule la règle “point_1_virginica_in” se maintient, décrivant ainsi à elle seule le concept virginica.
Concernant les règles destinées à décrire le concept de versicolor, la compétition est plus rude, les règles sont successivement sélectionnées parvenant à se maintenir toutes les deux.
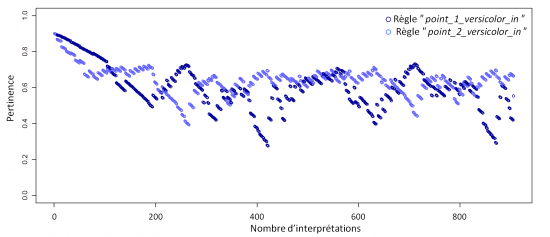
La compétition entre les règles destinées à décrire le concept de setosa illustre le cas d'une lutte avec rebondissement. La règle “point_1_setosa_in” se trouve au début souvent sélectionnée puis prend l'ascendant au détriment de la règle “point_2_setosa_in”. Mais avant l'oubli de cette dernière, des sélections successives surviennent et contribuent à l'ajustement de la règle, bien que la phase d'apprentissage soit dépassée. Cette situation s'explique par une sur-spécialisation de “point_1_setosa_in”, qui, au final, ne résistera pas à la remontée de “point_2_setosa_in” mieux adaptée et, finira dans l'oubli.
Influence des règles de récompenses
Une règle de récompense permet d’augmenter la pertinence d'une règle en fonction de la crédibilité de la règle de récompense et en fonction d'un taux.
Ce mécanisme permet soit de maintenir des règles à un certain de niveau de pertinence bien que leur fréquence de sélection soit faible au regard de sa dynamique, soit de faire en sorte d'amener la règle visée rapidement à une pertinence maximale afin de la conserver définitivement.
Dans l'exemple ci-dessous, c'est le second objectif qui sera mis en avant, aussi le taux de remboursement sera maximal :
<inference_engine> <frequency value="2"/> <forget value="0.1"/> <check_cover value="1.0"/> <bid_rate value="0.6"/> <reimbursement_rate value="0.6"/> <reward_rate value="1"/> <tax_rate value="0.01"/> </inference_engine>
Il y a plusieurs manières d'identifier la règle à récompenser. La manière la plus complexe consiste à utiliser deux marques, aussi c'est celle qui a été choisie pour illustrer le mécanisme d'identification des règles à récompenser. Par conséquent, un type de récompense et un type de marquage sont rajoutés aux modèles et, la structure perceptive “point” complétée afin d'indiquer que les règles de perceptions peuvent être récompensées. Le modèle complet se trouve dans le fichier “tutorial_2_assr.mod” et, le programme dans “tutorail_2_assr.prg”.
<perceptive_structure name="point"> <rewarded_by name="point"/> ... </perceptive_structure> <reward_type name="point"> <items> <item name="good"/> </items> </reward_type> <landmark_type name="point"> <items> <item name="this"/> <item name="that"/> </items> </landmark_type>
Dans l'exemple précédent, la classification des versicolor repose sur deux perceptions et empiète sur les points appartenant en théorie au virginica. Pour infléchir cet apprentissage, il est possible d'introduire un biais dans la dynamique de la pertinence en décidant de récompenser toutes les perceptions virginica. Évidement, ce biais n'est envisageable uniquement parce que la seconde règle de perception de virginica a été sélectionnée. Le fonctionnement de ce biais reposant sur les labels perçus, il ne sera effectif uniquement pendant la phase d'apprentissage.
En dehors, de cette solution, pour l'exemple, d'autres solutions peuvent être envisagées comme modifier les paramètres de la dynamique ou plus simplement modifier la pertinence initiale.
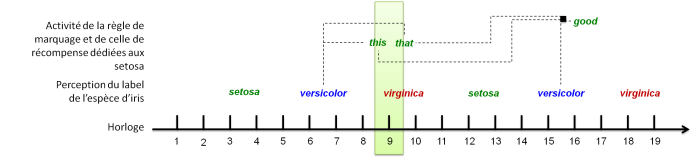
Le schème de récompense comporte alors une règle de récompense et deux règles de marquage. Les règles de marquage capturent l'évènement de perception pris entre les deux évènements de marquage inclus.
<scheme name="reward"> <rule name="reward_setosa"> <premise model="tutorial_2" category="landmark" type="point"> <information value="this" tolerance="INF"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="INF"/> </premise> <premise model="tutorial_2" category="landmark" type="point"> <information value="that" tolerance="INF"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="INF"/> </premise> <premise model="tutorial_2" category="perception" type="label"> <information value="versicolor" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="reward" type="point"> <information value="good"/> </conclusion> </rule> <rule name="landmark_setosa_1"> <premise model="tutorial_2" category="perception" type="label"> <information value="versicolor" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="500 ms" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="landmark" type="point"> <information value="this"/> </conclusion> </rule> <rule name="landmark_setosa_2"> <premise model="tutorial_2" category="perception" type="label"> <information value="versicolor" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="1000 ms" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="landmark" type="point"> <information value="that"/> </conclusion> </rule> </scheme>
Le chronogramme du schème de prédiction est le suivant :
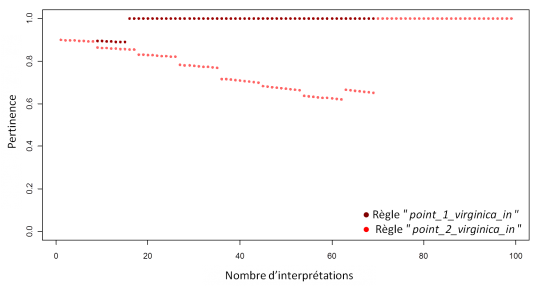
La récompense a pour effet d'augmenter considérablement la pertinence des règles dès qu'elles sont sélectionnées. Le graphique ci-dessous montre que la règle “point_virginica_data_1” atteint le maximum dès la première sélection. Avant sa première sélection, la pertinence de la seconde règle, “point_virginica_data_2”, décroit de sorte qu'il faudra deux sélections proches pour atteindre le niveau de pertinence maximale.
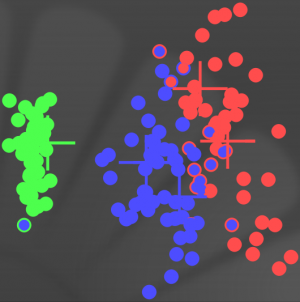
La classification avec récompense et la classification sans récompense reste semblable, hormis que le nombre de point étiqueté virginica augmente de trois comme l'illustrent les deux graphiques ci-dessous représentant respectivement les deux classifications avec et sans récompense où les croix représentent les centres des prémisses d'entrée :
Les familles de classification
Les mécanismes évoqués ci-dessus permettent de modéliser de nombreuses stratégies de classification. Voici quelques critères aidant à une catégorisation de ces stratégies :
Un premier critère porte sur la supervision de l'apprentissage, dans le formalisme nomo les trois familles de supervision peuvent être modélisées :
L'apprentissage supervisé, illustré dans le premier exemple sur l'adaptation des entrées. Les classes (les règles) et les données à apprendre sont explicites.
L'apprentissage non-supervisé, le maintien et l'adaptation des classes sont totalement soumis à l'ordre et à la fréquence de données. Les règles s'auto-organisent pour couvrir l'ensemble de l'espace des données et pour assurer leurs maintien et de fait leurs différences en fonction des paramètres liés à la dynamique de la pertinence.
Par exemple sur les données iris sans ACP, un ensemble de six règles de perception, dont les entrées sont tirées d'une distribution uniforme bornée par les extremums des axes, avec un taux d'enchère à 0.6 et celui de remboursement également à 0.6, donne une configuration stable de trois règles après deux présentations des données, le fichier “tutorial_2_ans.prg” contient le programme correspondant et illustre l'emploi d'une macro permettant de définir des patrons de règles :
<macro xmlns="http://www.nomoseed.org/sdk" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="template" active="true" name="points"> <csv xsi:type="extern"> <xi:include href="tutorial_2_ans.csv" parse="text"/> </csv> <template xmlns="http://www.nomoseed.org/template"> <rule name="point_in" fitting_nbr="0" relevance="0.9"> <premise model="tutorial_2" category="input" type="point"> <information value="#Comp_1" tolerance="0.15"/> <information value="#Comp_2" tolerance="0.1"/> <information value="#Comp_3" tolerance="0.25"/> <information value="#Comp_4" tolerance="0.1"/> </premise> <conclusion model="tutorial_2" category="perception" type="point"> <information value="#cluster"/> </conclusion> </rule> <rule name="point_out"> <premise model="tutorial_2" category="perception" type="point"> <information value="#cluster" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="point"> <information value="#cluster"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> <output value="0.0"/> </conclusion> </rule> </template> </macro> <macro xmlns="http://www.nomoseed.org/sdk" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="template" active="true" name="labels"> <csv xsi:type="extern"> <xi:include href="tutorial_2_ans.csv" parse="text"/> </csv> <template xmlns="http://www.nomoseed.org/template"> <rule name="label_out"> <premise model="tutorial_2" category="perception" type="point"> <information value="#cluster" tolerance="0"/> <credibility value="1" tolerance="INF"/> <timespan value="0" tolerance="0"/> </premise> <conclusion model="tutorial_2" category="command" type="label"> <information value="#cluster"/> <output value="#label"/> </conclusion> </rule> </template> </macro>
La figure ci-dessous illustre le résultat de cette classification sur deux des quatre dimenssions, les couleurs sont différentes que précédemment car la colorisation est en fonction du nombre de label apparaissant au cours l’exécution.
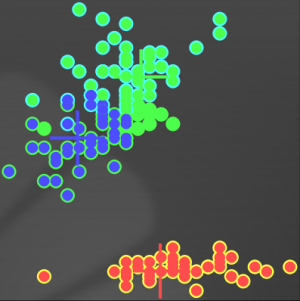
L'apprentissage semi-supervisé signifie qu'il existe des biais explicites à l'auto-organisation des règles, qui se traduit dans les conditions des règles, ou des mécanismes de récompense. Ces biais peuvent apparaître uniquement à un moment du programme, par exemple commencer une phase d'adaptation avec des contraintes explicites puis continuer l'adaptation sans ces contraintes initiales.
Un deuxième critère concerne l'évolution du nombre de règles :
Une classification stable signifie que le nombre de règles reste le même du début à la fin de l’exécution. Par exemple, le premier exemple concernant l'adaptation des entrées conserve le même nombre de règles où chacune correspond à une classe.
Une classification descendante correspond au cas où le nombre de classes initiales est volontairement élevé afin de couvrir tout l'espace puis d'éliminer les règles non pertinentes et, d'adapter les règles les plus pertinentes.
Une classification ascendante consiste à créer de nouvelles règles dans le cas où les règles existantes ne présentent pas une crédibilité suffisante ou autres critères. Les règles créées entrent alors en compétition avec les anciennes ou les complètent, l'objectif étant de couvrir de proche en proche l'espace fonctionnel de l'agent.
Le troisième critère porte sur la hiérarchisation des classes :
Une classification non-hiérarchique signifie que chaque classe se trouve au même niveau que les autres. Dans le formalisme nomo, cela revient à dire qu'une classe correspond à une et unique règle.
Une classification hiérarchique signifie qu'il existe des classes de classes. Dans le deuxième exemple, une classe d'iris s'appuie sur deux sous-classes correspondant chacune à une règle de perception.